Magic Draft Assistant
AI-powered overlay for competitive card drafting
In a Magic: The Gathering draft, you open packs of cards and pick one at a time, building a deck on the fly against other players. You have about 60 seconds per pick to evaluate 14+ cards across power level, color synergy, mana curve, and what your opponents are signaling through their picks. Drafts on Magic Arena cost real money, and the decisions are irreversible.
I built an AI companion tool to help with drafting that synthesizes all available information about a given set, from expert analysis, to podcasts, to card win rates, and creates real time recommendations as a learning tool for drafting in real time taking into account your current draft state.
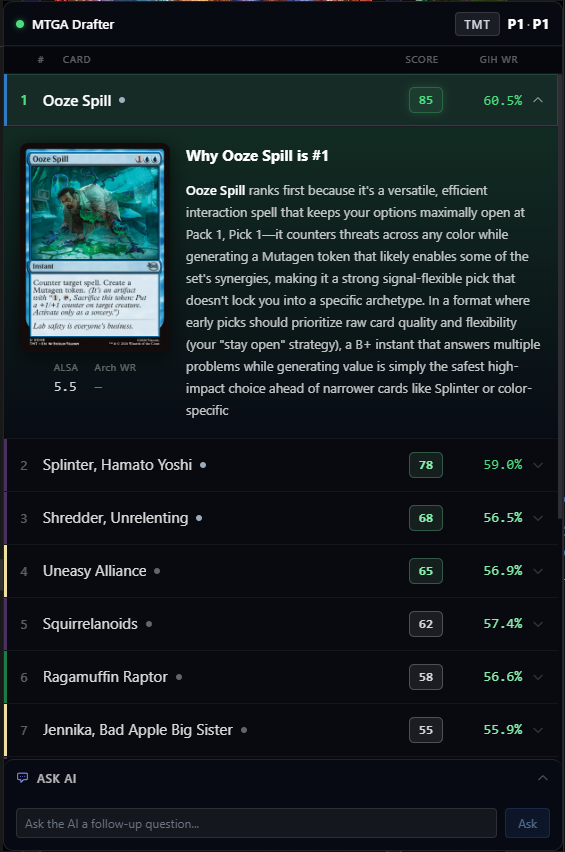
Building an amazing draft partner
A companion that sits with you draft in and draft out
The overlay sits on top of Magic Arena during drafts (or to the side provided enough screen real estate). It reads the game log in real time, pulls card statistics, synthesizes expert strategy from professional podcasts, and grades each card in the context of your specific pool, color signals, and archetype - streaming the results into the overlay as fast as the AI can think.
It's not just a stat display. It's an opinionated co-pilot that explains its reasoning, stays current with the evolving format meta, and adapts when you override its recommendations.
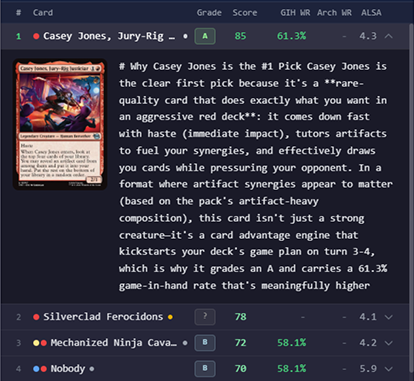
From data table to AI companion
The first iteration (seen here) threw TONS of information at the user. I quickly discovered that this information, while all technically useful, ended up making decision making more challenging given the time pressures of a real time draft. It's simply too difficult to parse and analyze large amounts of information, it needs to be reduced to only the bare minimum tablestakes for decision making.
For all the nuances and complexity that one would normally take their time on, I instead leaned on the AI to condense and explain the findings semantically, rather than putting that mental burden on the user.
Three stages, one smooth experience
The early versions waited for the AI to finish before showing anything - 8 to 12 seconds of a blank overlay. Unacceptable when you have 60 seconds to pick.
The solution was three stages that make the wait disappear:
1. Instant: a deterministic ranking based on heuristics - no AI call, no delay. The user has something to work with immediately.
2. Seconds later: the full AI ranking lands, reordering cards with contextual awareness of the pool, signals, and archetype. Cards stream in as JSON is parsed - the top 3 picks appear after 1-2 seconds.
3. Shortly after: detailed reasoning for the top picks auto-expands, showing why the AI made its call.
The AI takes the same amount of time either way. The architecture just removes the perception of waiting.
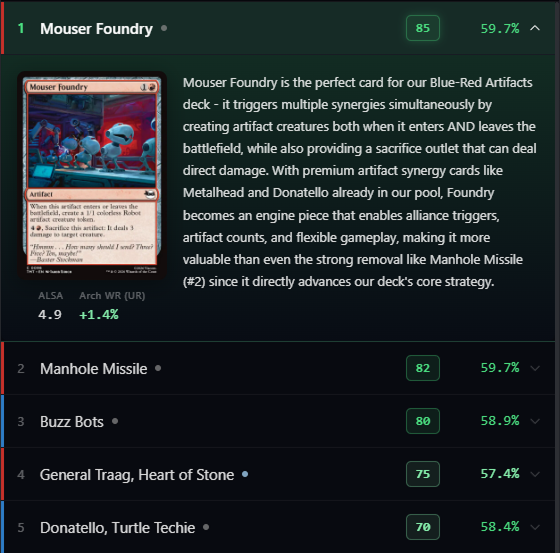
The AI adds weight, not authority
The tool doesn't tell you what to pick. It adds weight to your decision by showing its reasoning alongside hard data - so you can agree, disagree, or learn something.
The hard win rate for cards stays visible even when the AI ranks a card differently. A card might have a 50% baseline win rate but the AI ranks it first because it's exceptional in your specific archetype. Seeing both numbers lets you sanity-check: 'the AI sees something - let me read why' or 'the AI is wrong here, my deck needs removal.'
If you override the AI, it adapts. It buys into your direction and helps you from there - it doesn't keep pushing. The explanation makes errors visible too: you can see exactly which reasoning you disagree with.
Early results: my personal win rate moved from ~58% to ~62%. In competitive drafting that's the difference between above-average and near-professional territory. The sample size is still just me, but directionally strong.
Building the AI's expertise
The AI isn't just reading statistics. A custom pipeline fetches YouTube transcripts from professional draft podcasts, extracts structured knowledge - card grades, archetype advice, trap cards, synergy combos - and synthesizes across episodes into a set-specific knowledge file.
The result: Complete individual card evaluations, identifying 'trap' cards, deep archetype tier lists, and strategic insights that evolve as the format develops - updated automatically as new content and insights emerge online.
I built a draft simulator to test the AI's context offline. It replays draft scenarios and compares picks against expected outcomes. It immediately exposed prompt weaknesses and allowed me to iterate on how the recommendation engine functioned quickly.
Designing the context

Context as a design requirement
A typical draft has 42 picks. Each pick sends a 55K-token system prompt. Without optimization, that's 2.1 million input tokens per draft.
The system prompt is split into two independently cached blocks: static draft knowledge (~15K tokens, warmed on app startup) and set-specific content (~40K tokens, cached on the first pick). Anthropic's prompt caching gives a 90% discount after the first pick - every subsequent pick only pays full price on the ~2K-token dynamic prompt.
Total optimization: 2.1M tokens > ~290K per draft. 86% cost reduction. Combined with card reference compression (70% smaller) and a two-model strategy (Sonnet for ranking, Haiku for follow-ups at 10x cheaper), the tool is affordable enough to run every draft session.
Beyond the token cost - more context means greater turn around times for results. With a limited time window to make choices during a draft, every context token that doesn't earn its spot is stealing time from the user. Context crafting and curation isn't just plumbing - it's a design requirement to enable a good user experience.
Two-block cached system prompt
The system prompt is split into two independently cached blocks to maximize Anthropic's prompt cache hits. Block 1 is warmed on app startup before any draft begins. Block 2 is cached on the first pack of each draft. After that, every subsequent pick gets a 90% cost reduction on the system prompt.
The dynamic user prompt changes every pick and includes the full draft state: current pool with color commitments, mana curve, color signals with evidence, and all cards in the current pack with stats and oracle text - roughly 1,500-2,000 tokens per pick.
The prompt dynamically adjusts advice based on how far into the draft you are. Early draft (commitment < 30%): card grade is the primary factor, only bombs create real pull toward a color. Locked in (commitment > 75%): stay in your colors, only S/A+ bombs worth splashing, fill curve gaps.
A critical discovery during testing: the AI was evaluating cards based on how they synergize with other cards in the same pack - not realizing you can only take one and the rest go to opponents. This required an emphatic instruction that the other cards are going to opponents and should not factor into synergy evaluation.
# Block 1: Static (same for ALL drafts, pre-warmed on app startup)
blocks.append({
"type": "text",
"text": static_knowledge, # BREAD, CABS, signal theory, keywords
"cache_control": {"type": "ephemeral"},
})
# Block 2: Set-Specific (changes per draft format)
blocks.append({
"type": "text",
"text": set_knowledge, # Archetype guides, 400+ card reference
"cache_control": {"type": "ephemeral"},
})What's next

Two challenges to address before release
Monetization: I've optimized cost aggressively, but someone has to pay. Free means I subsidize a niche audience that won't generate ad revenue. 'Bring your own API key' is a terrible user experience, regardless of cost. I'll likely release this for free while I learn from users what makes it great for them, and eventually transition to an at-cost per set model.
Community reception: gaming communities are skeptical of AI right now. The launch needs to be framed with awareness of how AI is changing the landscape in gaming and culture. Moreover, the challenge of draft is the decision making, and this tool aids that greatly. I hope to position it as a learning tool that teaches you to draft better, not a crutch that replaces your judgment.